About
TERRIER (Temporally Extended, Regular, Reproducible International Event
Records) BETA is a new machine coded event dataset produced from a historical
corpus ranging from 1979 to 2016, available for download at
OSF. Event data generates structured records of
political events described in text in the form of (1) a source actor (2)
committing an action (3) against a target. The political events recorded in the
dataset include a wide range of political behaviors: meetings, statements,
provision of aid, protests, attacks, and violence. This dataset is an initial
beta release of the data, lacking event geolocation. We encourage researchers
to carefully check the data they use and to contact our team with any issues
they uncover regarding the data by opening a thread on our discussion
forum.
The dataset was produced by a team at the University of Oklahoma as part of the
National Science Foundation RIDIR grant “Modernizing Political Event Data”
SBE-SMA-1539302. This work used the Extreme Science and Engineering Discovery
Environment (XSEDE) JetStream at the Texas Advanced Computing Center and
Indiana University through allocation TG-SES180003. The Extreme Science and
Engineering Discovery Environment (XSEDE) is supported by National Science
Foundation grant number ACI-1548562. Any opinions, findings, and conclusions or
recommendations expressed in this material are those of the authors and do not
necessarily reflect the views of NSF or the U.S. government.
Download the data from OSF.
We have also produced a set of resources for Arabic event data. We’ve produced
a large set of gold standard records of protests and attacks in text, as well
as the spans associated with the actors for each. Those records are available
on Github. We’ve also
produced Arabic language CAMEO-style
dictionaries, which can
be used to map actors’ names and event text onto CAMEO categories.
Note: we are not affilied with the Terrier information retrieval group at the
University of Glasgow. Check out the excellent work they do on their
homepage.
The Team
| Photo |
Description |
 |
Jill Irvine, PhD, Presidential Professor of International and Area Studies, University of Oklahoma |
 |
Christan Grant, PhD, Assistant Professor of Computer Science, University of Oklahoma |
 |
Andrew Halterman, PhD Candidate, MIT |
 |
Khaled Jabr, MA Candidate, University of Oklahoma |
 |
Yan Liang, PhD Candidate, University of Oklahoma |
Getting Started
Download the data from OSF.
What is event data?
Event data, at its most basic, consists of a “triple” of information: an event, such as a protest or attack, performed by a source actor against a target. These events and actors are automatically recognized in text, extracted, and resolved to a defined set of codes, such that “demonstrated” and “rallied in the streets” would both be coded as a “Protest” event and “Angela Merkel” and “German Ministry of Defense” would both be represented as DEU GOV. Performing this process on many millions of documents produces a set of structured data that is much easier to analyze than the raw documents.
In producing event data, we build on the dominant paradigm of event coding in English, which consists of automatically comparing grammatically parsed sentence text with hand-defined dictionaries using an event coding tool. The tool follows instructions about how to combine the extracted noun- and verb phrases into a direct event with a source and target, and resolves the extracted text to specified set codes defined in an ontology. An automated event coding system thus consists of two components: a set of dictionaries that map noun and verb phrases to their corresponding actor and event codes in an ontology, and an event coder that applies these dictionaries to the text and makes decisions about how to combine individual actors and actions into coded events.
The ontology we use is the CAMEO ontology, which is the current standard coding ontology for most event data. CAMEO enforces a requirement for a source actor and target actor to go along with each event. Actors and events are each assigned hierarchical codes. Actor codes begin with high-level information comprising their country or international status, following by a functional role code, such as “GOV” or “MIL”, with secondary codes providing greater detail in some cases. Event codes can be aggregated into five top level classes, 20 intermediate event types, or around 200 low-level codes. Each code is documented in the codebook, available here.
For more details on how we created the Terrier event dataset, see our technical overview.
Terrier Dataset
The Terrier dataset was generated from roughly 200 million news stories from 500 news sources around the world, ranging in dates from 1979 into 2016. The raw text of each story was obtained from LexisNexis either though special API access and later through bulk dumps provided by LexisNexis on mailed hard disks. From these news articles, we produced around 60 million events.
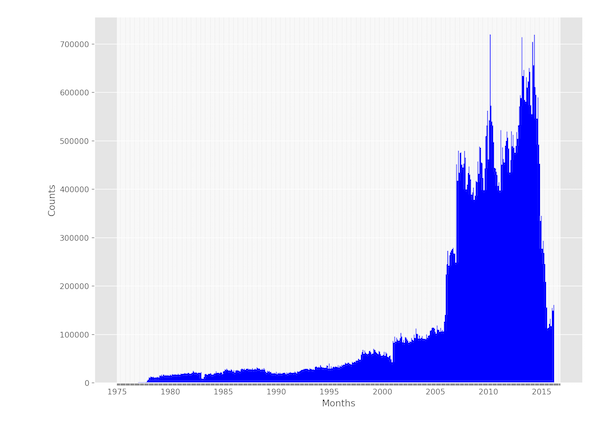
The number of events produced per month (below) shows a marked increase over
time, as more source text becomes available and as dictionary coverage
improves. This exponential increase is familiar from other event datasets and
poses challenges for researchers making over-time claims. Importantly, however,
it shows no major missing time periods.
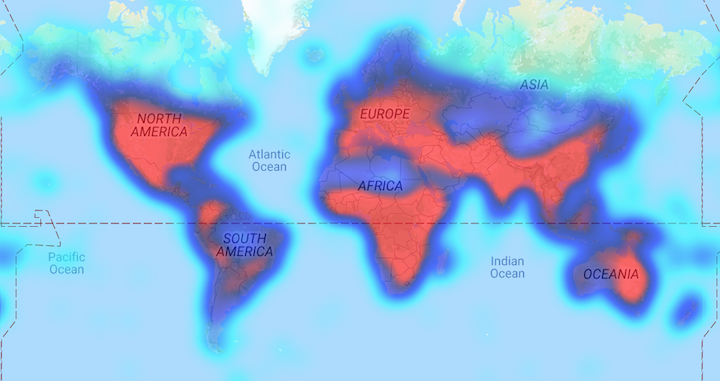
The events in TERRIER have initial geolocation information attached to them.
The geolocation process arbitrarily selects a location extracted by CLIFF-CLAVIN from the
sentence to the event in question. As with many maps,
a high-level plot of geolocated events reveals good coverage of the world’s
population density.
Codebook
The data available on OSF comes in two formats: JSON
and CSV. The JSON data includes field names for each entry, and the TSV does
not. These are the fields available for each event, presented in the order they
occur within the TSV files. For more details on what the different codes
represent, please consult the CAMEO
manual.
- “code” : The full CAMEO code of the coded event
- “src_actor” : The highest level code (e.g. country) for the source actor
- “month”: The two digit month code for the event (MM)
- “tgt_agent” : The primary role code for the target actor (e.g. “GOV”, “MIL”)
- “country_code” : The country the event is geolocated to (two digit ISO code)
- “year” : The YYYY date of the event/story
- “mongo_id” : The ID of the story in our database (mostly for internal use)
- “source” : The name of the news source that published the story.
- “date8” : The date of the event/story in YYYYMMDD format
- “src_agent” : The primary role code for the source actor (e.g. “GOV”, “MIL”)
- “tgt_actor” : The highest level code (e.g. country) for the target actor
- “latitude” : The latitude of the geolocated event
- “src_other_agent” : Other, secondary role codes for the source actor (semicolon separated)
- “quad_class” : The “quad” class of the event. 1 = verbal cooperation, 2 = verbal conflict, 3 = material cooperation, 4 = material conflict. (0 = neutral statement-type events)
- “root_code” : The CAMEO event root code (one of twenty)
- “tgt_other_agent” : Other, secondary role codes for the targer actor (semicolon separated)
- “day” : The day of the event/story in DD format
- “target” : The full target actor code (primary code plus role code).
- “goldstein” : a -10 to 10 conflictual-cooperative scale.
- “geoname” : The place name the event was resolved to
- “longitude” : The inferred longitude of the event
- “url” : (Unused for LexisNexis-based stories)
Sources
The English language sources used in TERRIER include LexisNexis’ complete
collection of articles published by the following sources between 1979 and
early 2016. (Note that LexisNexis does not possess many articles for
these sources in the 1980s and 1990s).
“Associated Press International”,
“The Associated Press”,
“BBC Monitoring”,
“BBC SUMMARY WORLD BROADCAST”,
“The New York Times”,
“AFP”,
“Xinhua”,
“The Globe and Mail”,
“ITAR-TASS”,
“McClatchy Washington Bureau”,
“AllAfrica”,
“UPI”,
“The Christian Science Monitor”,
“European Press Agency (EPA)”,
“South China Morning Post”,
“AAP Newsfeed”,
“The Guardian”,
“The Straits Times (Singapore)”,
“The Baltimore Sun”,
“Today’s Zaman”,
“The Sydney Morning Herald (Australia)”,
“Jerusalem Post”,
“Dawn (Pakistan)”“,
“Ghana News Agency”“,
“The Straits Times Singapore”,
“Guardian.com”,
“IPS - Inter Press Service”,
“Belfast Telegraph”,
“The Philadelphia Inquirer”,
“Hindustan Times”,
“Russia & CIS General Newswire”,
“Russia & CIS Energy Newswire”,
“Ukraine General Newswire”,
“Russia & CIS Business and Financial Newswire”,
“Kazakhstan General Newswire”,
“Czech Republic Business Newswire”,
“Russia & CIS Military Newswire”,
“Poland Business Newswire”,
“Hungary Business Newswire”,
“Central Asia General Newswire”,
“China Energy Newswire”,
“China Mining and Metals Newswire”,
“China Telecommunications Newswire”,
“China Pharmaceuticals & Health Technologies Newswire”,
“Philadelphia Inquirer (Pennsylvania)”,
“Knight Ridder Washington Bureau”,
“The Japan News”,
“The Daily Yomiuri(Tokyo)”,
“The Business Times Singapore”,
“ABC Premium News (Australia)”,
“FARS News Agency”,
“The Press (Christchurch, New Zealand)”,
“The Baluchistan Times”,
“Detroit Free Press (Michigan)”,
“TASS”,
“CNN Wire”,
“The Nation (AsiaNet)”,
“DAILY MAIL (London)”,
“MAIL ON SUNDAY (London)”,
“The Nation”,
“THE KOREA HERALD”,
“Central Asia & Caucasus Business Weekly”,
“The Japan Times”,
“Facts on File World News Digest”,
“Baltic News Service”,
“Daily Mail (London)”,
“Mail on Sunday (London)”,
“WAM Emirates News Agency”
Technical Details
Producing event data requires passing text through a series of tools to
grammatically parse sentences, recognize events, and record them in a
structured format. This process depends on recognizing actors, events, and
targets in text and comparing them to hand-built dictionaries to produce
standardized actor and event codes. TERRIER was produced with several open
source tools and tools produced and maintained by the Open Event Data Alliance.
Grammatical parsing
The first step in producing event data is to annotate the text with grammatical
markup to provide information about the structure of sentences and the
syntactic relationships between different parts of the sentence. The step
automatically identifies noun- and verb phrases and the relationships between
them, making it easier to determine who the actors are and what events are
occurring.
CoreNLP
To perform this step, we draw on the large body of work conducted in
computational linguistics and natural language processing over the past two
decades. Specifically, we use Stanford University’s
CoreNLP to provide provide a
constituency parse of each document.
Biryani
Because of the size of our corpus (~2TB, 300 million stories), running CoreNLP
was not a trivial task. We developed a distributed task-queue tool for
distributing CoreNLP jobs across a cluster of machines to speed
processing. Our tool,
biryani, uses a Kalman filter to
dynamically adjust the batch size and thread count in processing. More details
are available in an article
here.
Event Coding
The second major step in producing event data is to recognize political events
in text, which words in the sentence correspond with actors, targets, and
events, and which codes to assign to each actor or event.
Once CoreNLP generates grammatical information on the document, we are left
with the task of determining which noun phrases correspond to our “source” and
“target” actors, and which verb phrases could be events. In addition to finding
these spans of text, we also want to resolve them to predefined categories to
make them easily analyzable for social science research.
Petrarch2
The heart of our event data pipeline is Petrarch2, which locates actors,
events, and targets in text, compares them to dictionaries that map short
phrases to actor- and event codes, and returns a complete event. Petrarch2 is a
well known workhorse in automated event data. It is available for download
here and is described in a white
paper
here.
Birdcage
We produced a new pipeline to run Petrarch2 at scale over many millions of
documents. Although Petrarch2 is quite fast, it is natively parallel and also
requires slower pre- and post-processing steps, including geolocation and final
formatting. To bundle all of these steps together, we created
Birdcage, a distributed pipeline
that can quickly generate event data from CoreNLP-processed text.
The final dataset is available for download from OSF.
Tools and Publications
As part of producing the TERRIER event dataset, the event data team at the
University of Oklahoma has produced a set of tools and reported our work in
several publications. These efforts were funded in full or in part by the
National Science Foundation under award number SBE-SMA-1539302.
A complete set of Arabic language CAMEO actor, agent, and verb dictionaries
for producing Arabic language event data.
Arabic language event records, including gold standard event labels and actor spans.
Extract placenames from text and resolve them to their geographic coordinates.
An updated and improved version of Petrarch2, with full Python3 support.
Distributed, Dockerized CoreNLP with automated parameter tuning.
Produce event data from processed text, parallelized across cores or across a cluster.
Manage teams of annotators using Prodigy, an annotation tool.
Collect CAMEO-style dictionary entries from text and manage teams of annotators
Publications
Yan Liang, Christan Grant, Andrew Halterman, Jill A. Irvine, Khaled Jabr. New
Techniques for Coding Political Events Across Languages. IEEE 18th
International Conference on Information Reuse and Integration. Salt Lake City,
UT. 2018. [pdf] [slides]
Andrew Halterman, Jill A. Irvine, Christan Grant, Khaled Jabr, Yan Liang. Creating an Automated Event Data System for Arabic Text. Annual Meeting of the International Studies Association (ISA). San Francisco, CA. 2018. [pdf] [slides]
Andrew Halterman, Jill Irvine, Manar Landis, Phanindra Jalla, Yan Liang,
Christan Grant, Mohiuddin Solaimani, “Adaptive scalable pipelines for political
event data generation,” 2017 IEEE International Conference on Big Data (Big Data).
[link] [paper] [slides]
Andrew Halterman. Mordecai: Full Text Geoparsing and Event Geocoding. The Journal of Open Source Software, Vol 2, No. 9 (2017).
Discuss